Locality groups
If we need to read columns of a specific column family for many rows (using a common prefix), scan performance will degrade as column families increase in size.
Consider the webtable example:
If we wanted to get the language of all com.* pages, we would need to scan following column families:
anchor, which can be a very wide column familylanguagecontents, which is always huge because it stores raw HTML
language is just 2 bytes (alpha2 country code, e.g. DE, EN, …), but every row may require multiple kilobytes of data to be retrieved to get just the language. This heavily decreases read throughput of OLAP-style scans of large ranges.
To combat this, we can define a locality group, which can house multiple column families. Each locality group is stored in its own LSM-tree (a single partition inside the storage engine), but row mutations across column families stay atomic.
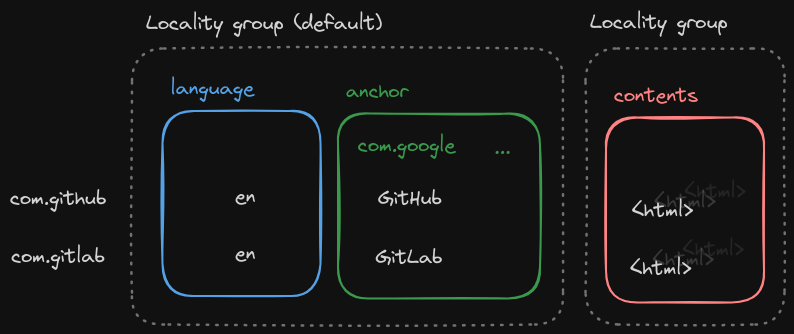
The data inside the locality group can likely be compressed much more efficiently, if the data is of the same type and similar in some way.
One downside of partitioning using locality groups is the increased read latency if we need to access column families that are not part of the same locality group.
Example: Without locality groups
Setup
First, let’s create a table no-locality-example:
curl --request PUT \ --url http://localhost:9876/v1/table/no-locality-exampleand two column families, title and language:
curl --request POST \ --url http://localhost:9876/v1/table/no-locality-example/column-family \ --header 'content-type: application/json' \ --data '{ "column_families": [ { "name": "language" }, { "name": "title" } ]}'By listing our table, we can see the column families have been created and are not part of any locality groups:
{ "message": "Tables retrieved successfully", "result": { "cache_stats": { "block_count": 0, "memory_usage_in_bytes": 0 }, "tables": { "count": 1, "items": [ { "column_families": [ { "gc_settings": { "ttl_secs": null, "version_limit": null }, "name": "language" }, { "gc_settings": { "ttl_secs": null, "version_limit": null }, "name": "title" } ], "disk_space_in_bytes": 0, "locality_groups": [], "name": "no-locality-example", "partitions": [ { "name": "_man_no-locality-example", "path": "/smoltable/.smoltable_data/partitions/_man_no-locality-example" }, { "name": "_dat_no-locality-example", "path": "/smoltable/.smoltable_data/partitions/_dat_no-locality-example" } ] } ] } }, "status": 200, "time_ms": 0}All data is stored in the _dat_no-locality-example partition.
Ingest data
Let’s ingest some data and query it (body is truncated for brevity):
curl --request POST \ --url http://localhost:9876/v1/table/no-locality-example/write \ --header 'content-type: application/json' \ --data '{ "items": [ { "row_key": "org.apache.spark", "cells": [ { "column_key": "title:", "type": "string", "value": "Apache Spark™ - Unified Engine for large-scale data analytics" }, { "column_key": "language:", "type": "string", "value": "EN" } ] }, // snip ]}'Query data
Let’s query our entire table using a scan with empty prefix, but
only return the column title::
curl --request POST \ --url http://localhost:9876/v1/table/no-locality-example/scan \ --header 'content-type: application/json' \ --data '{ "row": { "prefix": "" }, "column": { "key": "title:" }}'Smoltable returns (again, body truncated for brevity):
{ "message": "Query successful", "result": { "affected_locality_groups": 1, "bytes_scanned": 984, "cell_count": 8, "cells_scanned": 16, "micros_per_row": 17, "row_count": 8, "rows": [ // snip ], "rows_scanned": 8 }, "status": 200, "time_ms": 0}Note, how we scanned 1 KB of data, and 16 cells, but only returned 8 cells (because we filtered by the title column family). That means we have a read amplification of about 2.
Example: With locality groups
Setup
First, let’s create a table with-locality-example:
curl --request PUT \ --url http://localhost:9876/v1/table/with-locality-exampleand two column families, title and language, but move title into a locality group:
curl --request POST \ --url http://localhost:9876/v1/table/with-locality-example/column-family \ --header 'content-type: application/json' \ --data '{ "column_families": [ { "name": "language" } ]}'curl --request POST \ --url http://localhost:9876/v1/table/with-locality-example/column-family \ --header 'content-type: application/json' \ --data '{ "column_families": [ { "name": "title" } ], "locality_group": true}'By listing our table, we can see the column families have been created, and title is moved into a locality group:
{ "message": "Tables retrieved successfully", "result": { "cache_stats": { "block_count": 0, "memory_usage_in_bytes": 0 }, "tables": { "count": 1, "items": [ { "column_families": [ { "gc_settings": { "ttl_secs": null, "version_limit": null }, "name": "language" }, { "gc_settings": { "ttl_secs": null, "version_limit": null }, "name": "title" } ], "disk_space_in_bytes": 0, "locality_groups": [ { "column_families": [ "title" ], "id": "ij0SIQ_z0Ys9Qx_wMWyt6" } ], "name": "with-locality-example", "partitions": [ { "name": "_man_with-locality-example", "path": "/smoltable/.smoltable_data/partitions/_man_with-locality-example" }, { "name": "_dat_with-locality-example", "path": "/smoltable/.smoltable_data/partitions/_dat_with-locality-example" }, { "name": "_lg_ij0SIQ_z0Ys9Qx_wMWyt6", "path": "/smoltable/.smoltable_data/partitions/_lg_ij0SIQ_z0Ys9Qx_wMWyt6" } ] } ] } }, "status": 200, "time_ms": 0}Column families that are not title are stored in the _dat_with-locality-example partition, and title data is moved into the _lg_ij0SIQ_z0Ys9Qx_wMWyt6 partition.
Ingest data
Ingest the same data as before into with-locality-example.
Query data
curl --request POST \ --url http://localhost:9876/v1/table/with-locality-example/scan \ --header 'content-type: application/json' \ --data '{ "row": { "prefix": "" }, "column": { "key": "title:" }}'which returns (truncated):
{ "message": "Query successful", "result": { "affected_locality_groups": 1, "bytes_scanned": 610, "cell_count": 8, "cells_scanned": 8, "micros_per_row": 21, "row_count": 8, "rows": [ // snip ], "rows_scanned": 8 }, "status": 200, "time_ms": 0}We get the exact same result, however, we reduced scanned bytes down to 680 bytes, and halved scanned cells, achieving a read amplification of 1!
Example: Scanning another column family
Let’s scan the language column instead, which is still stored in the default partition.
curl --request POST \ --url http://localhost:9876/v1/table/with-locality-example/scan \ --header 'content-type: application/json' \ --data '{ "row": { "prefix": "" }, "column": { "key": "language:" }}'curl --request POST \ --url http://localhost:9876/v1/table/with-locality-example/scan \ --header 'content-type: application/json' \ --data '{ "row": { "prefix": "" }, "column": { "key": "language:" }}'no-locality-example (no locality groups) returns:
{ "message": "Query successful", "result": { "affected_locality_groups": 1, "bytes_scanned": 984, "cell_count": 8, "cells_scanned": 16, "micros_per_row": 18, "row_count": 8, "rows": [ // snip ], "rows_scanned": 8 }, "status": 200, "time_ms": 0}with-locality-example returns:
{ "message": "Query successful", "result": { "affected_locality_groups": 1, "bytes_scanned": 374, "cell_count": 8, "cells_scanned": 8, "micros_per_row": 15, "row_count": 8, "rows": [ // snip ], "rows_scanned": 8 }, "status": 200, "time_ms": 0}From 984 bytes down to 374, that’s a 62% decrease!